Analýza tokenů (v Excelu)
Tento nástroj umožňuje v programu Microsoft Excel hromadně analyzovat slovní tvary z korpusu, aniž by bylo nutné být připojen k internetu. Byl využit při vytváření podkladů pro popis skloňování obecných jmen ve staré češtině. Dokáže mj. spojovat uživatelem zadané slovní základy a koncovky a počítat výskyty výsledných tvarů v analyzovaném korpusu. Obsahuje několik dalších frekvenčních přehledů a analýz a je možné vytvořit si další.
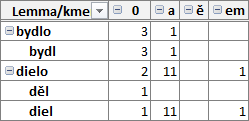
Na obrázku výše vidíte ukázku tabulky slovních tvarů, které se v korpusu vyskytují. Na řádcích bydl, děl a diel jsou tvarotvorné základy (dále jen „základy“), které patří k lemmatům bydlo a dielo. Ve sloupcích jsou koncovky (první je nulová). Průsečíku základu děl a nulové koncovky odpovídá slovní tvar děl, který se v ukázkovém korpusu staročeských textů (s více než 31 tisíci výskyty zhruba 22 tisíc různých tokenů) vyskytuje jednou; totožnou frekvenci má tvar diel s druhou podobou základu. Na řádku s lemmatem dielo jsou součty za obě podoby jeho základu. Nástroj nerozlišuje tvarová homonyma, např. tvar děl (Gpl) může náležet k lemmatům dielo a dělo (když do tabulky doplníme lemma dělo se základy diel a děl, započítají se tokeny k oběma lemmatům).
Požadavky
- K provozu Analýzy tokenů potřebujete Microsoft Excel 2010 nebo vyšší a doplňky PowerPivot a Power Query (oba od Microsoftu), které do Excelu přidají každý svou kartu do pásu karet.
- Oba doplňky dohromady vyžadují alespoň Windows 7, Internet Explorer 9 a .NET Framework 4.0 (nebo jejich novější verze).
- Power Query (stejně jako PowerPivot) je součástí Excelu 2016. Naleznete ho na panelu Data v sekci Načíst a transformovat (v anglické verzi Get & Transform).
Instalace
- PowerPivot pro Excel 2010 stáhnete z této adresy. Vyberte si 32bitovou verzi doplňku, protože Excel máte pravděpodobně také 32bitový. Pro větší objemy dat (řádově od desítek milionů tokenů) jsou vhodnější 64bitové verze.
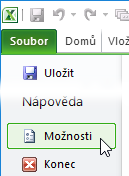
- Máte-li vyšší verzi Excelu (např. 2013), je možné, že PowerPivot už máte nainstalovaný spolu s Excelem, ale není aktivní. Otevřete si na kartě Soubor dialog Možnosti (v Excelu 2010 a 2013 v levém pruhu dole, nad tlačítkem Konec; v Excelu 2016 zcela dole pod položkou Účet).
- V tomto dialogu zvolte v levém
pruhu položku Doplňky, a pokud v seznamu vidíte PowerPivot
pro Excel mezi Neaktivními doplňky aplikací, vyberte ve spodní části
dialogu v nabídce Spravovat položku Doplňky modelu COM a klikněte na
tlačítko Přejít.
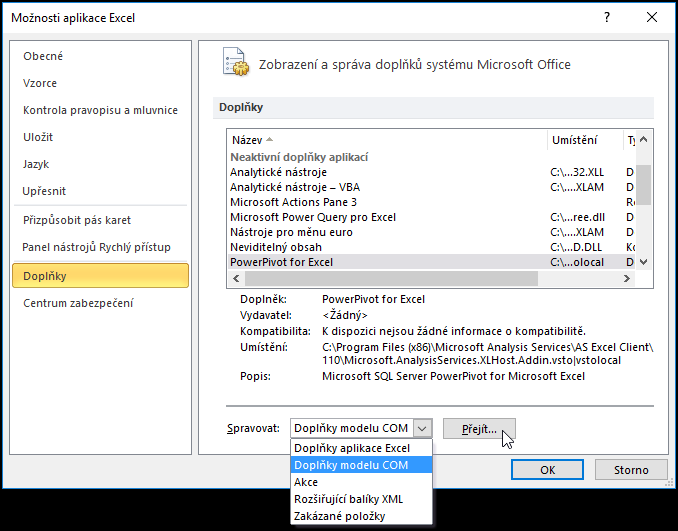
V dalším dialogu PowerPivot zaškrtněte a potvrďte.
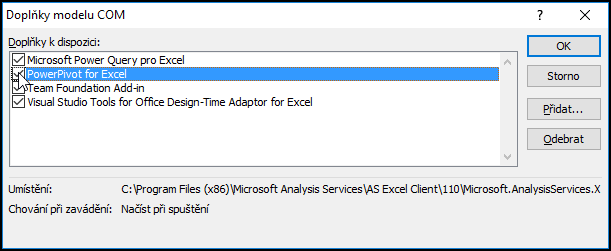
V Excelu by měla přibýt karta PowerPivot. Obdobnou ukázku, jak povolit PowerPivot v Excelu 2016, naleznete zde. - Pokud máte Excel 2013 a PowerPivot jste nenašli mezi nainstalovanými doplňky, je možné, že ho Excel ve vašem vydání neobsahuje (dostupný je pouze v samostatné verzi Excelu a v Office Professional Plus a Office 365 Professional Plus).
- Power Query nainstalujete stejně jako PowerPivot, případně ho v Excelu povolíte stejným způsobem. Pro Excel 2010 ho stáhnete z této stránky.
- Analýza tokenů je dostupná jako archiv ZIP, který stačí rozbalit do libovolné složky.
- Soubory s příponou
.txtnebudete potřebovat, slouží pouze na ukázku, jak vypadají zdrojová data, která Analýza tokenů obsahuje. Jde o tokeny pocházející z malé části korpusu staročeských textů. - O formátu podkladových dat a možnostech jejich přípravy vyjde článek v časopise Studie z aplikované lingvistiky.
Pojmy
- Při analýze délky tokenů v ukázkovém staročeském korpusu vycházíme z jejich grafického zápisu, v němž jednomu fonému odpovídají buď jeden (obvykle), nebo dva grafémy (u spřežky ch a dvojhlásek ie a uo). V dalším textu zavádíme jako grafický ekvivalent fonému termín fonogram. Např. koncovka -ích má stejně jako její staročeská podoba -iech právě dva fonémy/fonogramy, přestože se skládají ze tří, resp. čtyř grafémů.
- S tokeny (lingvistickými daty) nástroj pracuje jako s pouhými řetězci znaků; termín kmen se v nástroji používá volně pro počáteční grafémy tokenu (např. „rúš“), které mohou odpovídat skutečnému kmeni, častěji ale jen tvarotvornému základu.
- Slovem zakončení označujeme v nástroji i tomto manuálu koncové grafémy tokenu (např. „iech“, „ář“), v textu slouží na adekvátních místech také jako ekvivalent pro koncovku.
Představení
- Po otevření souboru
TokensAnalyzer.xlsxpovolte přístup k „externím zdrojům“. Těmi se myslí rozšíření PowerPivot a Power Query, jejichž instalace je popsána v předchozí části nápovědy.
- Analýza tokenů se otevře na posledním listu s přehledem vytvořeným z ukázkových tvarů (jeho část je vidět na obrázku v úvodu tohoto manuálu). Jak takový přehled vytvořit, se dozvíte v následujícím textu.
- Nejdříve přejděte na list Nastavení, který se vztahuje k zabudovanému seznamu tvarů.
- Volby, které mají vliv na výběr slovních tvarů z analyzovaného korpusu, jsou na
listu Nastavení tři. Buňka „Celkový součet“ v oranžové tabulce
je jen pomocná; její text se používá v kontingenčních tabulkách např. na
listu Tokeny (v pramenech).
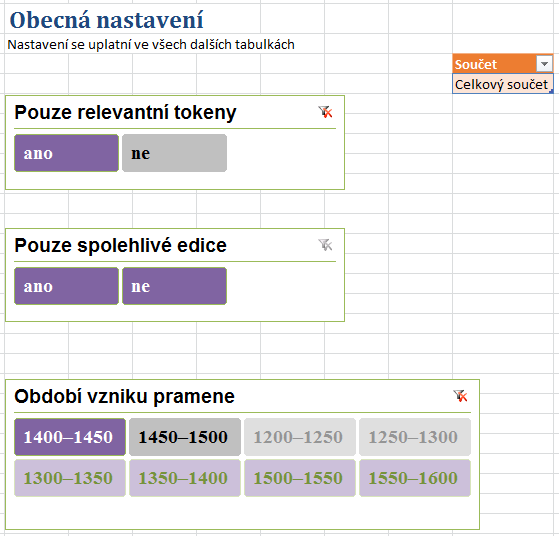
- Význam volby Pouze relevantní tokeny můžete zjistite, když spustíte doplněk
PowerPivot tlačítkem Okno doplňku PowerPivot na stejnojmenném panelu.
V tabulce
Tokenymá sloupec Je relevantní hodnotunepředevším u cizojazyčných tokenů, interpunkce a českých tvarů doplněných v edici editorem. - Volba Pouze spolehlivé edice se vztahuje k tabulce
Textyv PowerPivotu, která obsahuje metadata textů, z nichž tokeny pocházejí. Jako nespolehlivé se označují texty, které zatím neprošly redakcí a nejsou veřejně dostupné (mohou obsahovat chyby). - Součástí analyzátoru jsou texty ze dvou období: 1400–1450 (vybrané, sytá fialová) a 1450–1500 (pro ilustraci nevybrané, v sytě šedé). V seznamu pramenů jsou i texty z dalších období, ale neexistují pro ně žádné tokeny; proto jsou další období neaktivní.
- Přepněte na list Vzor, na němž se snažíme zjistit, jaké tvary jakých lemmat daného vzoru se v korpusu vyskytují a jak často. Vpravo vidíte tabulku s lemmaty, která končí na -o, a s variantními podobami jejich základů (např. nástupnické hláskové varianty). Vlevo od ní pak trojici tabulek s koncovkami (podle počtu fonogramů, z nichž se skládají), které po spojení se správným základem vytvoří validní slovní tvar.
- Vypadá to, že například tvary [v dobrém] „bydle“, „diele/díle“ a „rúše/rouše“ by se nevytvořily, protože mezi variantami základů nejsou „rúš/rouš“ a mezi koncovkami chybí -e. Tato koncovka, která na základě jazykového povědomí také do paradigmatu daných lemmat patří, ale ukázka ji zatím neobsahuje, je nástupnickou podobou -ě po ztrátě měkkosti, která proběhla u souhlásek během staročeského období (kromě l, které je nutno psát s koncovkou -e už na počátku staročeské doby).
- Zkuste chybějící podobu koncovky a základů doplnit. Rozšiřte tabulku
s koncovkami délky 1
a přidejte do ní „e“ a do tabulky lemmat a základů doplňte dva řádky s lemmatem
rúcho a podobami základu „rúš“ a „rouš“. V obrázku jsou změněné
řádky zvýrazněné tučně a podtržením.
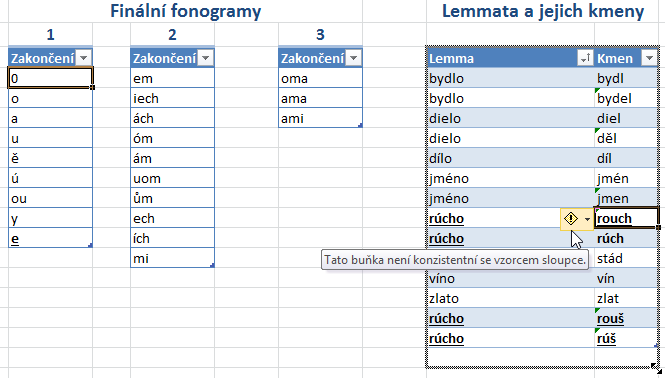
- Tabulku rozšíříte (nebo zkrátíte) potáhnutím za její spodní pravý roh (když se nad ním zobrazí oboustranná šipka). Jakmile zadáte lemma, vzorec automaticky odtrhne jeho poslední znak, aby jednoduše došel k základu (což dobře funguje u lemmat s jednopísmennou koncovkou jako bydlo nebo zlato). Tento vzorec se pro všechny možné podoby základu nehodí; vytvořený základ lze však přepsat. Nad takto upraveným základem se pak zobrazí zelená šipka s varováním Tato buňka není konzistentní se vzorcem sloupce, které můžete ignorovat.
- Chcete-li, můžete ještě obdobně změnit řádek s lemmatem „roucho“ a základem „rouch“ tak, že jako (hyper)lemma zadáte „rúcho“ (aby bylo pro všechny základy shodné) a základ přepíšete opět na „rouch“.
- K ověřovaní hypotézy budou nutné dvě věci: vygenerovat slovní tvary
ze základů a koncovek a vyhledat je v seznamu tokenů z korpusu.
Analýza tokenů obsahuje tvary z menšího průřezu staročeských textů.
K vygenerování tvarů přepněte na kartu Power Query, klikněte
na tlačítko Zobrazit panel a po straně se zobrazí seznam dvou
úkonů (předdefinovaných dotazů pro Power Query): Sloučení koncovek vzoru
a Generování tvarů včetně lemmat. (V obrázku je seznam pro úsporu
místa přesunutý nad tabulku.)
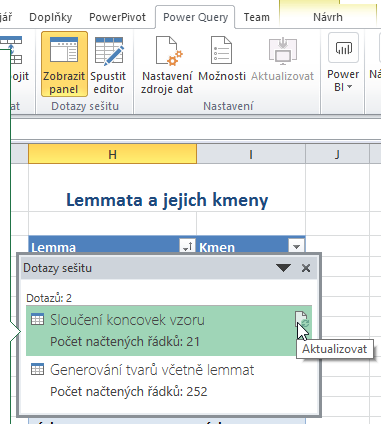
- Dotazy proveďte postupně, a to kliknutím na ikonku vpravo (s nápovědou Aktualizovat). Koncovek bude 22 a kandidátů na slovní tvary 308. Podívat se na ně můžete v pomocných tabulkách na listech Vzor (koncovky) a Vzor (tvary).
- Aktivujte ještě kartu PowerPivot a klikněte na tlačítko Aktualizovat vše.
Tak se nově vygenerované tvary (které mohou být i hypotetické) zpřístupní zbytku programu.
Tento úkon je nutné provádět po každém generování tvarů!
- Mějte na paměti, že pomocné tabulky Vzor (koncovky) a Vzor (tvary) se generují z dat v tabulce Vzor a o ruční úpravy těchto tabulek přijdete, jakmile kliknete v okénku Dotazy sešitu na ikonku Aktualizovat.
- Pro analýzu mnoha základů a koncovek (a od nich násobného množství vytvořených tvarů)
je vhodné přepnout na závěrečný list Tvary (lemma, kmen, zakončení). Všimněte si
nejdříve tří rámečků na filtrování podle lemmat, základů a koncovek
(pro ilustraci jsou seskupené u sebe). Otevřete stiskem pravého tlačítka
na kterémkoli z filtrů místní nabídku a klikněte na položku Aktualizovat.
Uvidíte, že zmizí lemma roucho (protože jsme ho sjednotili
s (hyper)lemmatem rúcho) a přibude bíle podbarvená koncovka -e.
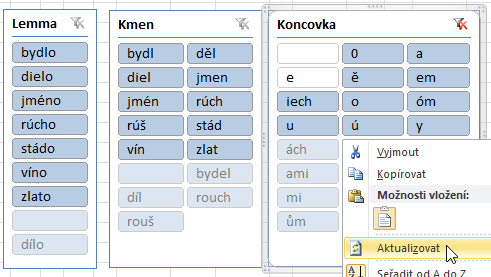
- Sytě modré položky jsou vybrané a existují k nim data. Světle modré položky jsou sice vybrané, ale data k nim nejsou. Bíle podbarvená koncovka je nová. Nezapomeňte na ni kliknout a tak ji aktivovat (měla by se zbarvit sytě modrou).
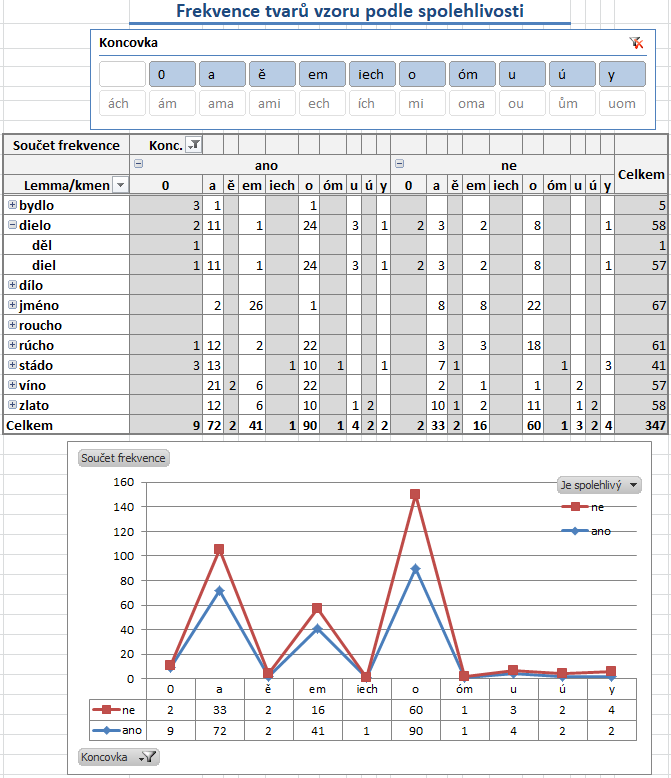
- Výsledek vidíte v kontingenční tabulce s počty slovních tvarů podle
lemmat (po rozkliknutí se zobrazí jednotlivé základy) a koncovek a nakonec spolehlivosti
pramene (té odpovídají sloupečky ano a ne).
Podkladem pro tabulku jsou vygenerované tvary, které se vyhledaly
v seznamu tokenů
z korpusu.
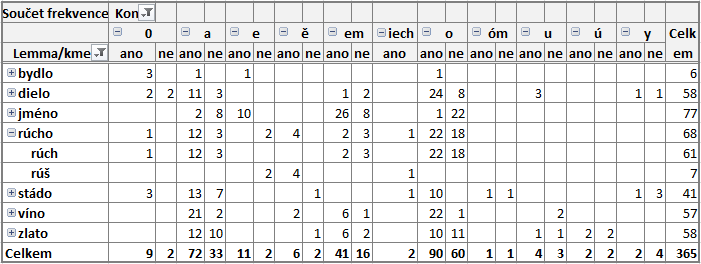
- Z tabulky je vidět, že tvary hyperlemmatu rúcho se v analyzovaném korpusu s hláskovou podobou ou (základy „rouch“ a „rouš“) nevyskytují. Přidaná podoba koncovky -ě/e se vyskytla v tvaru bydle. Původní podoba (-ě) i podoba po ztrátě jotace (-e) se našly u základu „rúš“ (rúšě i rúše). Nejlépe jsou doložené tvary s koncovkou -o a -a, tedy tvary mj. pro nominativ/akuzativ singuláru a genitiv singuláru, resp. nominativ plurálu.
Další analýzy
- Na listu Tokeny (v pramenech) vidíte počty tokenů v jednotlivých památkách a pramenech (památka Staré letopisy české je zastoupena dvěma prameny A a Q) a podle (předpokládaného) data vzniku rozděleného na 50letá období. Z dostupných období (na listu Nastavení) se zobrazují pouze dvě, která jsou zastoupená v textech. Do statistiky můžete zahrnout tokeny ze spolehlivých textů, které prošly redakcí, i z nespolehlivých.
- Nespolehlivé prameny (které jsou součástí Analýzy tokenů, ale
vypnuté, takže se nezobrazují na obrázku)
jsou
Povídka o Apolloniovi/ApolP,
Život Josefův a Aseneth/AsenM a
Klementinský Nový zákon/BiblKlemNZ.
Hodnocení spolehlivosti pramenů je součástí tabulky
Texty, kterou si můžete zobrazit v PowerPivotu.
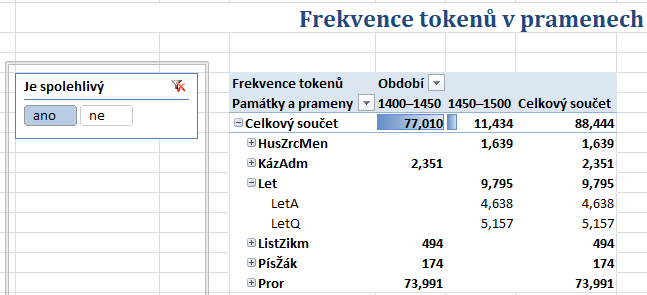
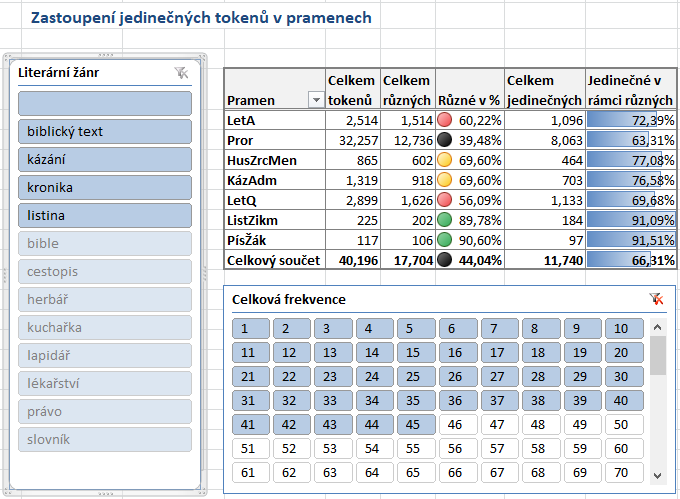
- K zjištění, do jaké míry se ve srovnatelných textech opakují tokeny
nebo které prameny se naopak vyznačují bohatstvím různých tvarů,
můžete využít list Tokeny (prameny, jedinečnost). Prameny lze
filtrovat podle žánru (neurčený žánr Husova
Zrcadla menšího/HusZrcMen
a žákovské písně Našě sestra Jana/PísŽák
se zobrazuje jako prázdné políčko).
Druhý filtr podle frekvence tokenů lze využít
k odhadu „bohatství“ pramene na základě
slov s vybranou frekvencí (četností); na obrázku jsou do této míry
zahrnuty tokeny, které se v pramenech vyskytují jednou až 45krát
(souhrnně jde o „vzácnější“ tokeny).
Všimněte si,
že bohatství pramene je nižší u delších textů
(v ukázce je nejnižší
u Proroků rožmberských/Pror);
proto je vhodné vzájemně srovnávat pouze texty podobné délky.
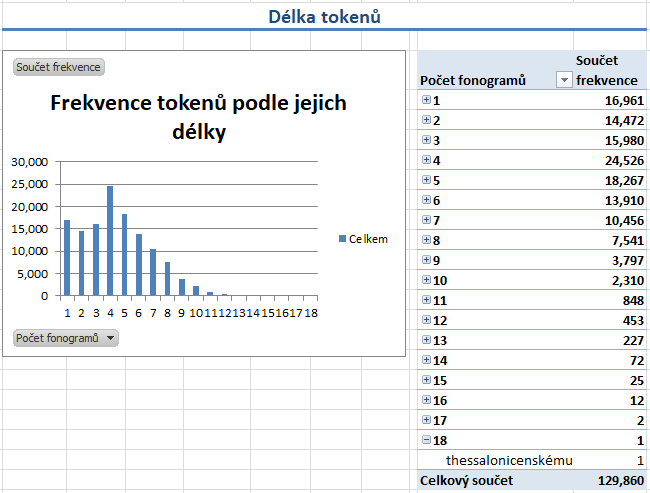
- List Tokeny (délka) obsahuje jednak graf
frekvence (histogram) tokenů podle jejich délky, tj. počtu fonogramů, nikoli grafémů, jednak tabulku s počty tokenů dané délky.
Kliknutím na symbol
 se
rozbalí seznam všech tokenů odpovídající délky s počtem výskytů jednotlivých tokenů.
Z obrázku je zřejmé, že nejdelší token se v korpusu vyskytuje pouze jednou.
se
rozbalí seznam všech tokenů odpovídající délky s počtem výskytů jednotlivých tokenů.
Z obrázku je zřejmé, že nejdelší token se v korpusu vyskytuje pouze jednou.
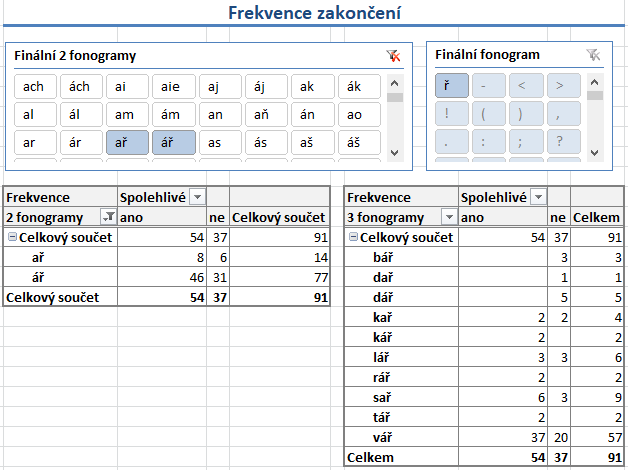
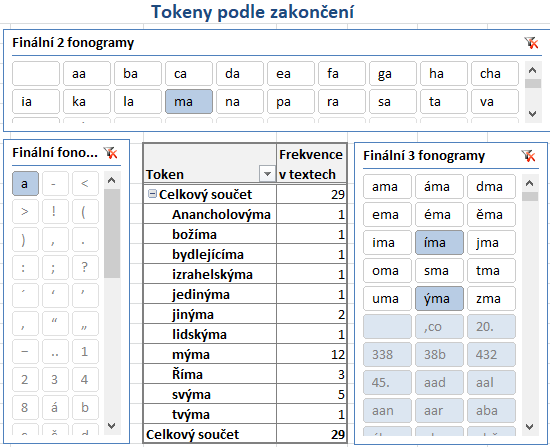
- Smyslem listu Finální fonogramy je analýza zakončení
tokenů, zejména hledání výskytů
koncovek a přípon. Filtry Finální 2 fonogramy a Finální fonogram slouží
k výběru tokenů podle zakončení (na obrázku jsou zvolené
přípony -ař a -ář).
Spodní dvě tabulky se generují podle nastaveného filtru a obsahují nikoli celé tokeny, ale dvou-
a třífonémová zakončení a počty jejich výskytů. Dalším filtrem
 v záhlaví každé
tabulky je možné zobrazovat nebo skrývat sloupce s počty ze spolehlivých nebo nespolehlivých
pramenů.
v záhlaví každé
tabulky je možné zobrazovat nebo skrývat sloupce s počty ze spolehlivých nebo nespolehlivých
pramenů.
- Na listu Tokeny (zakončení) můžete podle zakončení
filtrovat tabulku všech tokenů.
Ve filtrech jsou dostupná zakončení délky jednoho, dvou
(všimněte si zakončení -cha)
a tří fonogramů a uplatňují se zároveň, tj. např. při výběru finálního fonogramu se ve zbývajících filtrech zaktivní pouze ty položky, které končí na zvolenou položku.
- List Tvary (zakončení, spolehlivost) obsahuje podobně jako list Tvary (lemma, kmen, zakončení) tabulku s frekvencí tvarů vytvořených kombinací uživatelem zadaných základů a koncovek, přičemž se odlišují počty tvarů ze spolehlivých a nespolehlivých textů. Filtrovat lze podle koncovek a spolehlivosti zdroje.
- Spojnicový graf vespod listu vychází ze stejných dat jako generovaná tabulka.
Rozdíl je v prezentaci počtu tokenů z nespolehlivých
textů: červená čára vyjadřuje celkový počet tvarů ze spolehlivých textů (modrá čára)
i nespolehlivých.